
Press Release
Platon Aims To Become The Public Infrastructute Of Privacy Computing To Open Up Business Prospects For The Crypto Space
In the Information Age, Data Becomes a New Factor of Productivity
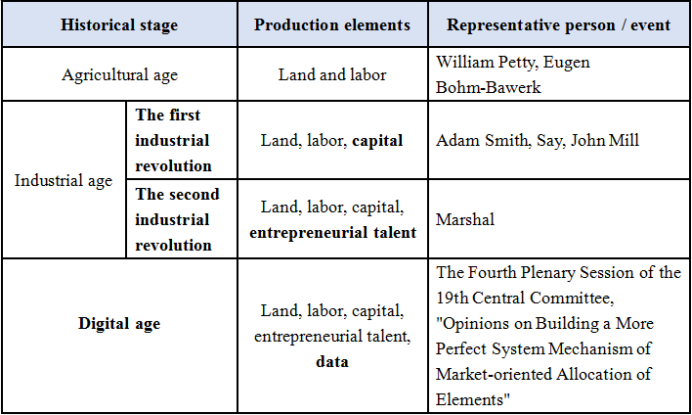
In economics, factors of production, also known as production inputs, are essential resources for the production of goods and services. In his epochal work “Principles of Economics”, famous British economist Marshall put forward the theory of four factors of production — land, labor, capital and entrepreneurial talent. National income (NI) is the reward of four factors, and that is, national income (NI) = labor wage (w) + land rent (r) + capital interest (i) + operating profit (π). This “four-in-one formula” sums up the core of western economic production theory and distribution theory, which has been widely accepted for more than a century.
However, factors of production are a historical category that evolves with the development of economy and society. The birth and development of the Internet has changed the mode of production, life and consumption, and it promoted many important and profound changes, and played an increasingly important role in economic development, social life and national governance. The full exploitation and effective utilization of all kinds of data has raised production efficiency to an unprecedented level. Data has become an indispensable factor in economic activities and a new generation of production factors after land, energy, population and food.
Table – Production Factors at Different Stages
Privacy Brings Data Dilemma and MPC Realizes Data Collaborative Computing
Nowadays, people have already extended their social activities to the network space. Every day, people contribute data continuously to the network space. A large amount of data is collected, calculated, analyzed, excavated and this goes beyond the original data level of information value.
However, because of the plain text nature of the data, the owner loses ownership of the data once the data is granted to others for use. Therefore, to ensure the privacy protection of data, a huge amount of data managed by enterprises cannot be exchanged and co-calculated with the data held by other enterprises, which is why a large number of data cannot generate value.
The emergence of privacy computing ends this dilemma. Yao Qizhi, a member of the Chinese National Academy of Sciences, proposed secure multi-party computing (MPC) in 1982. In a nutshell, participants have to enter information to calculate an agreed function. In addition to the accuracy of the calculations, they must also protect the privacy of each participant’s input data. Specifically, there are now n participants, each of whom, xi, is aware of the xi they entered, who together calculate a pre-agreed function f (x1 ,…, xn) = y. In this way, all participants will get the final y value, but they will not be able to know the specific data entered by the other participants. Thus, with local data not aggregated and privacy not divulged, each party can still achieve a common desired result by performing the operations of the given logic.
Privacy computing opens up huge business prospects for the digital world (Crypto Space)
Bitcoin’s pioneering combination of virtual currencies and peer-to-peer payment systems open the door to decentralization. With the introduction of intelligent contract function, Ethernet has greatly improved the scalability of blockchain, and all kinds of applications can be deployed on blockchain. Because of these characteristics, early public blockchain networks such as Bitcoin and Ethernet have been developed, attracting a large number of blockchain and encryption enthusiasts in the world, and many traditional institutions have been entering the area of blockchain, exploring various possibilities of decentralization.
The combination of privacy computing and blockchain is expected to put data ownership back in the hands of data producers, meaning that vast amounts of data can be counted without affecting privacy and ownership, so that the owners can profit and data can burst out with greater value. Therefore, the blockchain project based on privacy calculation is naturally suitable for the commercial practice in the fields of financial, medical, scientific research, government affairs, and logistics and so on.
“Operator” PlatON network for blockchain data
PlatON, the representative project of the combination of privacy computing and blockchain currently, is based on the basic attribute of blockchain and is supported by privacy computing network, and provides the next generation Internet infrastructure protocol with the core characteristics of “computing interoperation”. PlatON’s vision is to become the public infrastructure for privacy computing of the next generation, publishing privacy computing algorithms through contracts, and implementing MPC protocols with data providers and computing nodes for privacy protection requirements, so as to realize cooperative computing of data. PlatON, designed to price data flows, is all about computing and data, which is the most fundamental part of future human production. PlatON can achieve large-scale application landing and commercial scenario implementation:
For example:
I. Build a wider credit collection network. The public chain that provides private computing can provide user with customizable computing logic template and multi-party access mode, and in the case that the access party’s data does not need to be collected and shared, only the credit inquiry results are output to the demander, and the original data can be encrypted and stored in the blockchain system to meet all kinds of audit needs.
II. Supply chain financial infrastructure. The public chain of private computing is based on blockchain technology and cryptography algorithm, which can provide a platform solution for supply chain finance to digitally identify, process and transfer assets. Construct a new financial financing model of supply chain in which the information of the upstream and downstream enterprises can be shared symmetrically, the credit value of the core enterprises can be transmitted, the business tickets can be split and the risk can be controlled, and provide convenient data traceability for the supervision and enhance the service efficiency of the industry as a whole.
To build the public infrastructure for the digital age, PlatON continuously optimizes technology, iterates the underlying infrastructure, and breaks through the “impossible triangle” in terms of performance. “Impossible triangle” means that it is difficult to achieve both a good “decentralization” and a good “security” of the system in a blockchain and a high “transaction processing performance” at the same time. The most well-known blockchain projects in the industry are Bitcoin, Ethernet, and EOS. At present, using native Token transfer performance test method and EOS under the same testing conditions, PlatON has achieved a comprehensive performance leader in the quasi-real environment, and will continue to focus on the data field and accelerate the construction of data market.
About Author
Disclaimer: The views, suggestions, and opinions expressed here are the sole responsibility of the experts. No Digi Observer journalist was involved in the writing and production of this article.

Shanghai, China, August 3rd, 2026, ZEX PR WIRE, WasabiCard, a global payment infrastructure platform, announced its participation in ChinaJoy 2026, taking place from July 31 to August 2, 2026, at Shanghai New International Expo Centre. The company will showcase its global payment solutions at Booth W5-A102, connecting with businesses and industry partners from the gaming, internet, and digital entertainment sectors.

As digital businesses continue expanding into international markets, efficient and scalable payment infrastructure has become increasingly important. At ChinaJoy 2026, WasabiCard will demonstrate how its payment solutions help enterprises simplify global payment operations, improve financial efficiency, and support cross-border business growth.
Through its global payment infrastructure platform, WasabiCard enables businesses to access key capabilities including global card issuing, cross-border payments, and global payouts. The platform supports a wide range of business scenarios, including advertising payments, corporate expenses, SaaS subscriptions, creator payments, affiliate commissions, supplier settlements, and global workforce payments.
WasabiCard’s card issuing solutions allow enterprises to launch virtual cards, physical cards, and customized card programs through flexible integration options. With support for digital wallet integration, including Apple Pay and Google Pay, businesses can manage global spending more efficiently across different operational scenarios.
The company’s global payout capabilities enable businesses to distribute funds across 200+ countries and regions, supporting multiple fiat currencies and streamlined payout workflows for employees, creators, contractors, partners, and suppliers.
With a focus on compliance and security, WasabiCard maintains a global regulatory framework, including U.S. MSB, Canada MSB, U.S. MTL, PCI DSS Level 1, and Visa TPA certifications, supported by comprehensive risk management processes covering KYB, KYC, KYT, and AML requirements.
During ChinaJoy 2026, the WasabiCard team will meet with enterprises, partners, and industry leaders to discuss how modern payment infrastructure can help digital businesses improve operational efficiency and expand globally.
Visitors are invited to visit WasabiCard Booth W5-A102 from July 31 to August 2, 2026, to explore global payment solutions and connect with the team.
About WasabiCard
WasabiCard is a global payment infrastructure platform enabling enterprises, fintech companies, and internet-native businesses to build scalable payment solutions through global card issuing, cross-border payments, and payout capabilities.
Its platform supports virtual and physical card programs, multi-currency settlement, global fund distribution, and embedded payment solutions designed for modern global commerce. WasabiCard powers payment use cases across media buying, SaaS subscriptions, global payroll, creator payments, treasury management, and digital financial applications.
Disclaimer
About Author
Disclaimer: The views, suggestions, and opinions expressed here are the sole responsibility of the experts. No Digi Observer journalist was involved in the writing and production of this article.
Press Release
From Early Hardship to Building a $35.8M Portfolio: Don Kilam Shares the Business Philosophy Behind His Entrepreneurial Journey
Don Kilam reflects on the experiences, business principles, and organizational strategies that contributed to the growth of Kilam International while expanding educational resources for entrepreneurs.
Las Vegas, Nevada, United States – Every entrepreneurial journey begins with a defining moment. For Don Kilam, founder of Kilam International, that moment emerged from overcoming significant personal and financial challenges that ultimately reshaped his perspective on business ownership, organizational planning, and long-term enterprise development.
From navigating periods of financial hardship and homelessness to building a business portfolio valued at approximately $35.8 million, Kilam’s story reflects years of entrepreneurship, strategic planning, and continuous learning. Rather than describing his experience as a universal roadmap to success, Kilam says his journey demonstrates the importance of understanding how businesses are organized, managed, and developed over time.
According to Kilam, one of the most significant lessons he learned was the value of treating business activities with the same discipline and structure expected of established organizations. That philosophy has since become a central theme of the educational resources developed through Kilam International, where entrepreneurs are encouraged to learn about business organization, operational planning, and responsible financial management.
A Journey That Changed His Perspective
Before establishing his current business portfolio, Kilam faced numerous personal and financial obstacles that shaped his approach to entrepreneurship. Those experiences motivated him to better understand how businesses operate, how organizations are structured, and how long-term planning can contribute to sustainable business growth.
“Building a business changed the way I viewed entrepreneurship,” said Kilam. “I came to appreciate the importance of organization, planning, accountability, and understanding how businesses function. Those experiences continue to influence the educational work we do today.”
Kilam explains that many entrepreneurs focus primarily on generating revenue, while often overlooking the importance of building a solid operational foundation. His experience led him to place greater emphasis on business structure, documentation, financial organization, and strategic planning as part of managing a growing enterprise.
Business Practices That Supported Growth
Throughout the development of Kilam International, Kilam adopted a number of business practices that he believes contributed to the company’s evolution.
One area of focus involved operating through formal business entities, including limited liability companies (LLCs) and trust structures where appropriate. According to Kilam, these organizational decisions were made as part of broader business planning and in consultation with professional advisors based on the company’s operational needs.
The company also invested in maintaining organized accounting systems and business banking practices to support financial management and administrative oversight. Kilam says accurate financial records and consistent operational procedures became increasingly important as business activities expanded.
As the company grew, Kilam explored a variety of business financing opportunities to support expansion initiatives. He notes that financing decisions were evaluated based on business objectives and available opportunities, while emphasizing that funding options vary significantly depending on the nature of each business and should always be assessed with appropriate professional guidance.
Kilam International also continued to explore business development opportunities through strategic partnerships, private business initiatives, and educational programs. These activities contributed to the company’s broader focus on entrepreneurship, business education, and organizational growth.
In addition, the company diversified its business interests across multiple sectors, including real estate, digital education, and online business communities. Kilam says diversification formed part of the company’s long-term business strategy and reflected its commitment to developing multiple areas of enterprise activity rather than relying on a single business segment.
Expanding Entrepreneurial Education
Drawing from these experiences, Kilam International has expanded its educational initiatives to help entrepreneurs better understand business organization, operational planning, accounting practices, and enterprise management.
The company’s educational resources discuss topics including business entity selection, organizational planning, financial recordkeeping, responsible business administration, and long-term operational development. Kilam emphasizes that these materials are intended to encourage informed decision-making and should not be interpreted as legal, tax, investment, or financial advice.
“Our goal is to encourage entrepreneurs to think beyond the initial stages of launching a business,” Kilam said. “Building a sustainable organization requires continuous learning, responsible planning, and a willingness to adapt as opportunities and challenges evolve.”
Through its online community and digital educational platforms, Kilam International continues to publish content designed to help entrepreneurs better understand the operational aspects of running a business. The company says future educational initiatives will continue to focus on entrepreneurship, organizational development, and business management while encouraging individuals to seek qualified professional advice for decisions involving legal, financial, or tax matters.
While every entrepreneurial journey is unique, Kilam believes that education, planning, and responsible business practices remain valuable components of long-term enterprise development. His story—from overcoming hardship to building a diversified business portfolio—serves as the foundation for Kilam International’s ongoing commitment to supporting entrepreneurship through education rather than promises of financial outcomes.
Contact Info:
Name: JEFFERY MCBRIDE JR
Email: Send Email
Organization: KILAM INTERNATIONAL
Address: 8565 S EASTERN AVE , SUITE 150, LAS VEGAS, NEVADA, United States
Phone: 702-200-4900
Website: https://www.donkilam.com/
About Author
Disclaimer: The views, suggestions, and opinions expressed here are the sole responsibility of the experts. No Digi Observer journalist was involved in the writing and production of this article.
Press Release
Rasmala Global Sukuk Fund Named Winner of Two 2026 LSEG Lipper Fund Awards for Best Fund over 10 Years
Dubai, United Arab Emirates, August 3rd, 2026, FinanceWire
Independent recognition of a decade of consistent, risk-adjusted performance
The Rasmala Global Sukuk Fund was recognised with the 2026 LSEG Lipper Fund Awards for Best Fund over 10 Years in the Bond Sukuk Global USD classification, winning across two award universes: Global Islamic and MENA Markets.
The LSEG Lipper Fund Awards have, for more than three decades, recognised funds that have delivered consistently strong risk-adjusted performance relative to their peers. Winners are determined using LSEG Lipper’s independent, proprietary quantitative methodology, based on the Lipper Leader rating for Consistent Return over three-, five-, and ten-year periods.
The Rasmala Global Sukuk Fund is a UCITS sub-fund of an open-ended, Luxembourg-incorporated umbrella investment company. One of the longest-running global sukuk funds of its kind, the Fund invests in a diversified portfolio of Shariah-compliant assets, comprising primarily investment-grade sovereign, government-related and corporate sukuk, without reference to any specific benchmark. The Fund is dynamically managed and targets both income and capital appreciation, with a monthly distribution of dividends, and has navigated multiple market cycles within a risk-managed framework.
The awards come at a period of heightened volatility for global fixed income. Fitch Ratings has noted that the sukuk market’s recovery in 2026 hinges on sustained regional stability, with issuance expected to remain below 2025 levels amid ongoing geopolitical uncertainty.¹ Against this backdrop, an independent award recognising consistent, risk-adjusted performance over a full decade underscores the value of an actively managed, disciplined approach through changing market cycles.
“We’re proud to see the Rasmala Global Sukuk Fund recognised among the best over ten years. In a market that continues to test investors, an independent award for consistent, risk-adjusted performance over a full decade speaks to the strength of our active management and the trust our investors place in us. It reflects the disciplined, long-term approach that defines how we manage capital at Rasmala,” said Eric Swats, Senior Executive Officer, Rasmala Investment Bank Limited.
About Rasmala Investment Bank Limited
Rasmala Investment Bank Limited (“Rasmala”) is an independent alternative investment manager serving Gulf-based investors including pension funds, family offices, corporates, endowments, and financial institutions. The firm is located in the DIFC, Dubai, UAE, and regulated by the Dubai Financial Services Authority (DFSA). It is a wholly owned subsidiary of Rasmala Investment Holdings (DIFC) Limited (“Rasmala Holdings”). For more information, visit www.rasmala.com.
¹ Market context sourced from publicly available third-party commentary: Fitch Ratings, “Global Sukuk Issuance Recovery Hinges on Regional Stability” (Non-Rating Action Commentary), 8 July 2026, fitchratings.com/research/non-bank-financial-institutions/global-sukuk-issuance-recovery-hinges-on-regional-stability-08-07-2026. Provided for context only.
Important information/disclaimer
For Professional Client only. This document constitutes a financial promotion and is directed only at persons who meet the DFSA’s definition of a Professional Client and must not be relied upon by any other person. It does not constitute an offer, solicitation or investment advice. Past or projected performance is not necessarily a reliable indicator of future results; the value of investments can fall as well as rise, and investors may not recover the full amount invested. RIBL is authorised by the DFSA to operate an Islamic Window and has appointed a Sharia Supervisory Board that reviews and approves its Islamic Finance products. The LSEG Lipper Fund Awards is awarded by LSEG Lipper based on its independent quantitative methodology; details are available at lipperfundawards.com. Prospective investors should read the Fund’s prospectus and KIID/PRIIPs-KID and seek independent advice before investing. The awards referred to herein should not be construed as a recommendation to purchase or invest in the Fund and does not guarantee future performance. Nothing in this communication excludes or limits any duty or liability owed by Rasmala Investment Bank Limited under applicable DIFC laws or the DFSA Rulebook.
Contact
Tim Hydari
Senior Executive, Branding & Investor Communications
Rasmala Investment Bank Limited
media@rasmala.com
+971 4 424 2700
About Author
Disclaimer: The views, suggestions, and opinions expressed here are the sole responsibility of the experts. No Digi Observer journalist was involved in the writing and production of this article.
WasabiCard Heads to ChinaJoy 2026 to Power Global Business Growth
From Early Hardship to Building a $35.8M Portfolio: Don Kilam Shares the Business Philosophy Behind His Entrepreneurial Journey
Rasmala Global Sukuk Fund Named Winner of Two 2026 LSEG Lipper Fund Awards for Best Fund over 10 Years
Benzinga Money Article Discusses How to Become Part of the 12% of Retirees Who Have Achieved the Recommended $550,000 Minimum Retirement Savings Threshold
Apu Apustaja Conquers New York with Lively Street Ads, Including Times Square Billboard
Bay Smokes Maintains Quality Amid Legislative Changes in the Hemp Industry


-
Press Release1 week ago
Biomaser and LatinLook Strengthen PMU Partnership in Argentina
-
Press Release1 week ago
Transport BPO Launches First-Week-Free Dispatch and Call Answering Service for Transportation Businesses
-
Press Release1 week ago
CLT Academy Launches Indian Markets and Crypto Programs in Dubai
-
Press Release1 week ago
Stephen Cheatham: Why Most Structural Failures Are Not Surprises
-
Press Release5 days ago
Apex Financial Ltd: Chief Strategic Analyst Christopher James Carter Unveils RWA-AI-Safeguards
-
Press Release2 days ago
The Future of Preventative Healthcare! Dr. Sundardas Annamalay and Dr. Narjit Singh’s Newly Released Book Sheds Light on Cellular Health
-
Press Release5 days ago
TRX Spot and Perpetuals Listing Launches on Backpack, Expanding Access to the TRON Ecosystem
-
Press Release2 days ago
Shattering Industry Norms: Don Kilam Drives Global Expansion Backed by $35.8M Portfolio